Table of contents
Introduction
Matching methods for causal inference match similar units together before estimating treatment effects from observational data, in order to reduce the bias introduced by confounding variables. Crucially, a distance measure must be chosen that determines what it means for units to be “similar”. While many matching methods match units based off one-dimensional summaries of their covariates (such as propensity or prognostic scores), Almost Matching Exactly (AME) methods match units that are directly similar in their covariates, with similarity on more important covariates prioritized. This results in matches that are both interpretable and high quality. For more details on Almost Matching Exactly, visit our website here.
This package has implementations for two algorithms in the AME framework that are designed for discrete observational data (that is, with discrete, or categorical, covariates): FLAME (Fast, Large-scale Almost Matching Exactly) and DAME (Dynamic Almost Matching Exactly). FLAME and DAME are efficient algorithms that match units via a learned, weighted Hamming distance that determines which covariates are more important to match on. DAME finds optimal sets of covariates that units can match on, where optimality is determined by how important covariates are. FLAME approximates the DAME solution, greedily searching for good covariate sets. More specifically, for each treated unit $t$, DAME solves the following optimization problem:
\[\text{argmax}_{\boldsymbol{\theta} \in \{0, 1\}^p}\;\boldsymbol{\theta}^T\mathbf{w}\quad\text{s.t.}\\ \quad \exists \ell\;\:\text{with}\;\: T_{\ell} = 0 \;\:\text{and}\;\: \mathbf{x}_{\ell} \circ \boldsymbol{\theta} = \mathbf{x}_{t} \circ \boldsymbol{\theta}\]where $\circ$ denotes the Hadamard product, $T_{\ell}$ denotes treatment of unit $\ell$, and $\mathbf{x}_t \in \mathbb{R}^p$ denotes the covariates of unit $t$. That is, given fixed covariate importances or weights $\mathbf{w}$, DAME finds the highest weight covariate set for which $t$ can be matched to at least one control unit. In practice, DAME and FLAME do not iterate over units, but rather over covariate sets. DAME solves this problem efficiently through a downward closure property: because matching on an additional covariate will never be detrimental, DAME only considers matching on a covariate set if it has already considered matching on all of its supersets. FLAME approximates the solution to this problem via a greedy, backwards stepwise selection procedure: it iteratively matches units on a set of covariates and then drops a covariate from future consideration. Typically, in practice, the weights $\mathbf{w}$ are determined dynamically; for each set of covariates under consideration, a regression is run on a held out dataset to predict how well they jointly predict the outcome. Their error in doing so is known as the Predictive Error or $\mathtt{PE}$. To ensure that FLAME’s greedy approach also makes a reasonable number of matches, out of the covariate sets under consideration, FLAME matches on the one maximizing match quality $\mathtt{MQ}$, defined as $\mathtt{MQ} := C \cdot \mathtt{BF} - \mathtt{PE}$, where $C$ is a hyperparameter. The balancing factor, $\mathtt{BF}$, at an iteration is defined as the proportion of control units, plus the proportion of treated units, that are matched by the update to the next covariate set. In this way, FLAME encourages making many matches (lowering variance of treatment effect estimates) and matching on covariates important to the outcome (lowering bias of treatment effect estimates).
In both algorithms, the main matched group (MMG) of a unit i is defined as the units it first matches to; that is, that it matches to on the highest quality covariate set considered. Both algorithms allow for matching with replacement (in which units can match on multiple different covariate sets); this allows units to belong to multiple matched groups (MGs) – once in their MMG and several times more in the MMGs of other units. For more details, please see (Wang et al. 2020) linked here and (Dieng et al. 2019) linked here.
Making Matches
To illustrate the basic package functionality, we’ll work with some toy data we can create using the included FLAME::gen_data function.
set.seed(24)
library(FLAME)
n <- 500 # Observations
p <- 5 # Covariates
# Data to match
data <- gen_data(n, p)
# Data to compute PE and determine which covariate sets to match on
holdout <- gen_data(n, p)
Note that all our covariates are categorical because FLAME and DAME are designed to work with discrete data:
head(data[, 1:p])
#> X1 X2 X3 X4 X5
#> 1 1 2 2 1 4
#> 2 2 3 3 3 1
#> 3 3 2 1 3 1
#> 4 2 1 2 1 2
#> 5 3 3 1 4 2
#> 6 2 2 2 3 1
While the covariates needn’t be coded as factors before being passed to FLAME or DAME, all covariates will be assumed to be categorical. A user may of course bin continuous variables prior to passing them to FLAME or DAME; however, we generally caution against this approach as naive coarsenings of continuous variables can fail to properly adjust for bias when estimating treatment effects. A coarsening may be acceptable in certain domain-specific contexts if performed by a domain expert. Otherwise, there are other algorithms in the AME framework that allow mixed discrete and continuous covariates. For more details, see (Parikh, Rudin, and Volfovsky 2018) linked here and (Morucci et al. 2020) linked here.
In addition to the covariates to match on, data contains an outcome and a treated column:
names(data)
#> [1] "X1" "X2" "X3" "X4" "X5" "outcome" "treated"
These can have any names if they are appropriately relayed to the matching algorithm via treated_column_name or outcome_column_name, but default to 'treated' and 'outcome'.
The outcome may be continuous (if numeric with more than two unique values), binary (if a two-level factor or numeric with unique values 0 and 1), or multi-class (if a factor with more than two levels). The outcome may also be omitted from the matching data, but it must be included in the holdout data as it is required to learn covariate importance. Both FLAME and DAME focus on binary treatments and the treatment column must accordingly be coded either as logical or as binary numeric.
Given data of this general form, we can run FLAME and DAME with their default parameters. This will match units on the covariates – here, X1, X2, X3, X4, X5 – and output information about the matches that were made. Here, we call FLAME, though the call to DAME is analogous.
FLAME_out <- FLAME(data = data, holdout = holdout)
#> FLAME stopping: predictive error would have risen 25% above the baseline.
The resulting stopping message informs us that FLAME stopped dropping covariates once they became too important for predicting the outcome; see the Early Stopping Arguments subsection below for more details.
FLAME and DAME return a list of class ame, which by default contains 4 entries:
names(FLAME_out)
#> [1] "data" "MGs" "cov_sets" "info"
The first, FLAME_out$data contains the original data frame with several modifications:
- There is an extra logical column,
FLAME_out$data$matched, that indicates whether or not a unit was matched. This can be useful if, for example, you’d like to use only the units that were matched for subsequent analysis:
matched_data <- FLAME_out$data[FLAME_out$data$matched, ]
-
There is an extra numeric column,
FLAME_out$data$weightthat denotes on how many different sets of covariates a unit was matched. By default, this will be 1 if a unit is matched and 0 otherwise. With thereplace = TRUEargument, however, units are allowed to match several times on multiple sets of covariates and their values forweightcan therefore be greater than 1. These weights can be used when doing regression adjustment after matching to estimate treatment effects. -
The columns denoting treatment and outcome in the data will be moved after all covariate columns (this is likely to change in a future release).
-
If
replace = FALSE, there will be an extra column containing a matched group identifier for each unit. All units with the same identifier share the same main matched group. -
If
estimate_CATEs = TRUE, there will be an extra column containing a CATE estimate for each unit.
The second, MGs is a list, each entry of which contains the units in a single matched group.
FLAME_out$MGs[[1]]
#> [1] 1 84
That is, the first unit in the dataset was matched to unit 84.
The third, cov_sets is a list whose i’th entry contains the covariate set not matched on in the i’th iteration.
FLAME_out$cov_sets
#> [[1]]
#> NULL
#>
#> [[2]]
#> [1] "X5"
#>
#> [[3]]
#> [1] "X4" "X5"
Thus, we can see that FLAME first matched exactly on all covariates, then dropped covariate X5, then covariates X4 and X5, and then terminated.
And the fourth, info, is a list containing miscellaneous information about the matching specifications. This is primarily used internally by *.ame methods.
Analyzing Matches
After either FLAME or DAME has been run, the resulting ame object and the associated matched data can be analyzed in a variety of ways. The FLAME package provides functionality for a few quick, post-matching analyses, via print, plot, and summary methods and the functions MG and CATE.
Printing an ame object will give some information about the matching procedure and estimate an average treatment effect, if possible:
print(FLAME_out)
#> An object of class `ame`:
#> FLAME ran for 3 iterations, matching 434 out of 500 units without
#> replacement.
#> The average treatment effect of treatment `treated` on outcome `outcome` is
#> estimated to be 4.8666474.
Summarizing an ame object gives additional information on 1. the number of matches formed, 2. average treatment effect estimates, and 3. the matched groups formed:
(FLAME_summ <- summary(FLAME_out))
#> Number of Units:
#> Control Treated
#> All 244 256
#> Matched 214 220
#> Unmatched 30 36
#>
#> Average Treatment Effects:
#> Mean Variance
#> All 4.87 0.00941
#> Treated 4.86 0.0105
#> Control 4.87 0.0105
#>
#> Matched Groups:
#> Number 128
#> Median size 3
#> Highest quality: 228 and 27
In the above, the ‘highest quality’ matched groups – 228 and 27 – are the two largest made on the highest quality covariate set. Manual inspection of these groups and their CATE estimates can be useful.
Plotting an ame object by default outputs 4 plots, any subset of which can be selected via the which_plots argument. They illustrate:
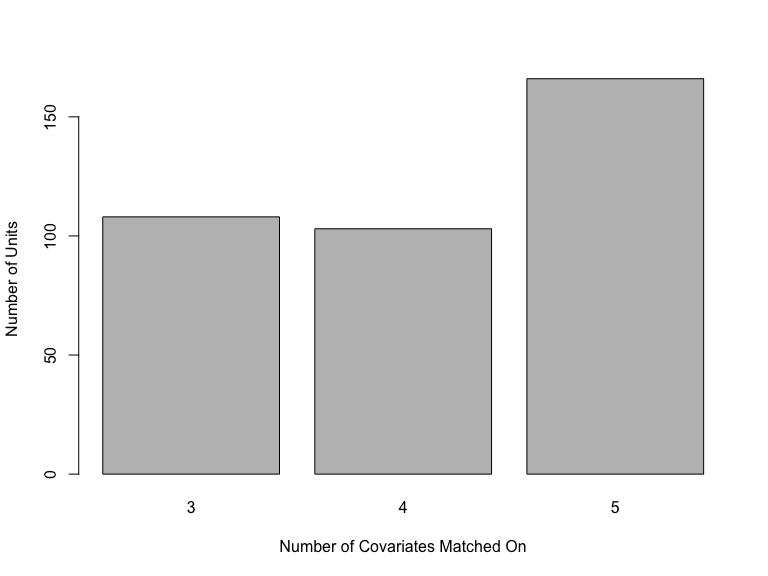
- The number of covariates different units matched on, with higher numbers indicating higher quality matches. This can give an indication of the overall quality of the matches that were formed. If most of the matches were made on a very small subset of the covariates, this may mean that most of the matches are of low quality, unless the PE of that subset is particularly low; this can be investigated by supplying
return_PE = TRUEto the originalFLAMEorDAMEcall. If, instead, there were many matches on large numbers of covariates and also on small numbers, a user may wish to rerun the algorithm with an additional early stopping constraint to ensure that a greater fraction of the matches are high quality.
plot(FLAME_out, which_plots = 1)
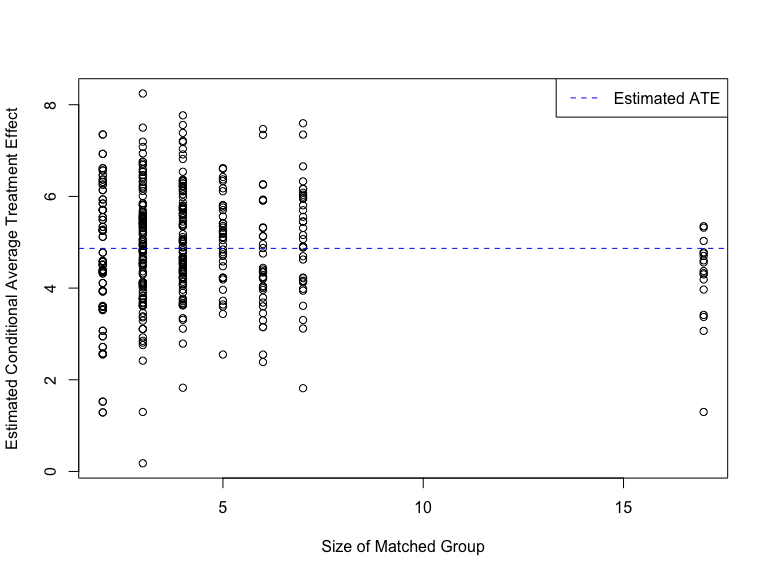
- Estimated CATEs as a function of matched group size. This can be useful for determining if larger matched groups – which have more stable CATE estimates – tend to have systematically higher or lower CATEs than average.
plot(FLAME_out, which_plots = 2)
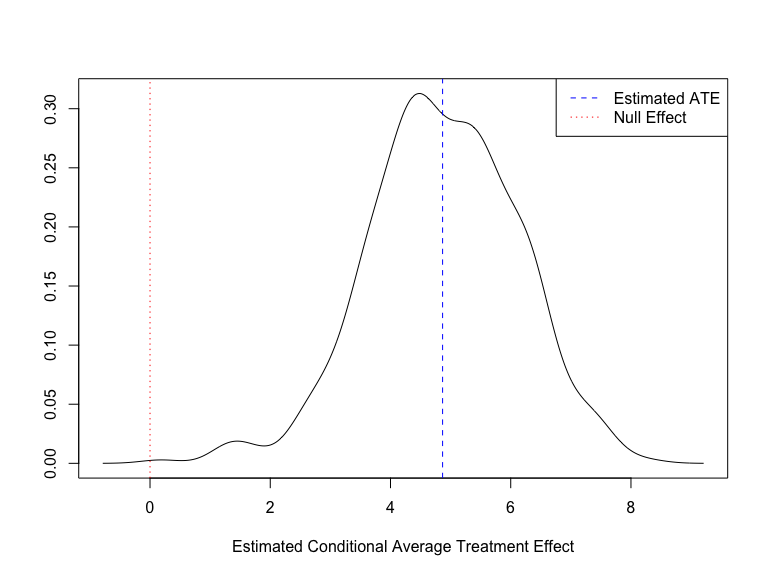
- An estimated density of CATE estimates, with the ATE marked. This gives insight into the variance of an ATE estimate and other features in the density, such as multi-modality, may suggest the existence of subpopulations of interest in the data.
plot(FLAME_out, which_plots = 3)
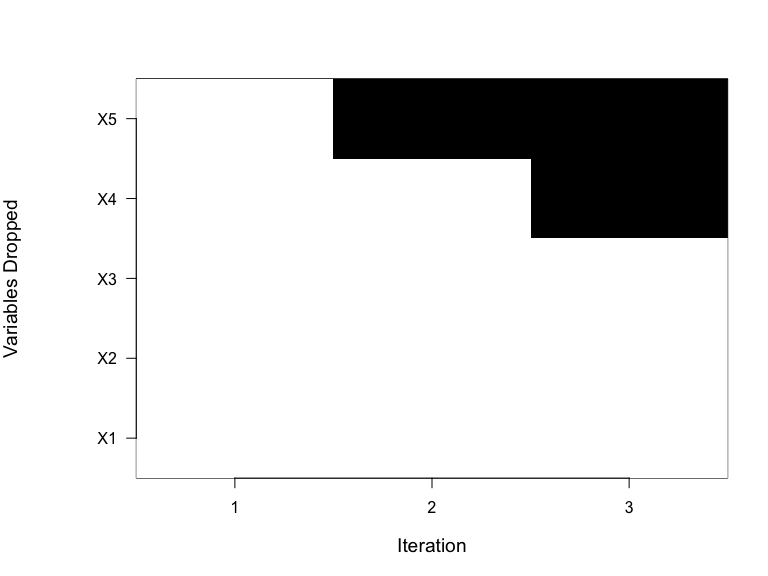
- A heatmap showing the order in which covariate sets are dropped. Without manually looking at PE values returned from the algorithm, this can give a quick visual sense of which covariates were most useful for predicting the outcome. As we saw, by inspecting
FLAME_out$cov_sets, below, we see that on Iteration 1 matches were made on all variables, on Iteration 2 they were made on all variables butX5, and on Iteration 3 they were made on all variables butX5andX4.
plot(FLAME_out, which_plots = 4)
Lastly, the functions MG and CATE take in vectors of units and return their matched groups and CATE estimates. Based off the summary above, we can run these on some units belonging to high quality matched groups:
high_quality <- FLAME_summ$MG$highest_quality
MG(high_quality, FLAME_out)
#> [[1]]
#> X1 X2 X3 X4 X5 treated outcome
#> 228 3 3 3 3 2 1 34.40411
#> 236 3 3 3 3 2 0 30.61004
#> 309 3 3 3 3 2 0 30.92045
#> 351 3 3 3 3 2 0 30.23918
#> 358 3 3 3 3 2 1 33.57794
#> 473 3 3 3 3 2 1 34.68919
#> 490 3 3 3 3 2 0 30.06894
#>
#> [[2]]
#> X1 X2 X3 X4 X5 treated outcome
#> 27 2 3 2 3 3 1 14.52208
#> 36 2 3 2 3 3 1 15.02916
#> 150 2 3 2 3 3 0 12.22630
#> 163 2 3 2 3 3 0 10.02043
#> 360 2 3 2 3 3 0 11.62386
#> 411 2 3 2 3 3 0 10.40921
CATE(high_quality, FLAME_out)
#> Mean Variance
#> 228 3.764094 0.1473901
#> 27 3.705668 0.3294528
Each element in the output of MG corresponds to a different input unit. In this case, we see that both units matched on all covariates, which is what makes them high quality.
Runtime and Storage Considerations
Runtime
FLAME and DAME are implemented using efficient bit-vectors computations, which makes them scalable to datasets large in both n and p. Nevertheless, runtime may be appreciable (on the order of hours) for datasets with hundreds of thousands of rows and dozens of covariates. The most expensive tasks that contribute to this runtime are 1. matching units given a set of covariates and 2. finding the next set of covariates to match on. While there is not much that can be done about
- there is a good deal of flexibility the user has in controlling the time taken by 2. In this step, every covariate set eligible to be matched on is used to predict the outcome on the holdout data; assuming matching is not terminated early, this entails running O(p2) many regressions for FLAME and O(2p) for DAME. Furthermore, both of the regression methods implemented in this package for computing PE,
PE_method = 'ridge'andPE_method = 'xgb'perform cross-validation in order to ensure that the regressions are of high quality, imposing additional computational cost on the procedure. However, if a user believes that more efficient methods (e.g. vanilla linear regression) or different specifications of the implemented methods (e.g. fewer folds of cross validation or fewer parameters to cross validate over) are sufficient to predict the outcome well, then a function can be supplied toPE_methodgiving the user complete control over the prediction procedure and allowing for considerable speedups. Examples are given in the section Computing Predictive Error below.
If a user wishes to match using DAME on a dataset with many covariates, a reasonable option may be to start by using FLAME for a few iterations to rapidly eliminate irrelevant covariates and then switch to DAME to generate higher quality matches on higher quality sets of covariates. This can be done by supplying the n_flame_iters argument to DAME. Setting this argument to 5, for example, rapidly eliminates 5 covariates via FLAME’s greedy backwards selection procedure and then switches to DAME. In the presence of irrelevant covariates (which are likely to exist in high-dimensional settings), such an approach should yield nearly identical treatment effect estimates much more quickly.
Our implementation of FLAME and DAME runs a different regression for each covariate set under consideration, to ensure that it is capable of predicting the outcome well. However, if a user already has measures of covariate importance that they would like to use within the matching procedure, they can pass these to the algorithm via the weights parameter. In this case, 0 regressions have to be run because a sequence of covariate sets is already implicitly defined by the weights, dramatically accelerating the matching procedure. One way to produce such weights would be through an initial regression of the outcome on all covariates, from which some measure of covariate importance is computed and supplied to the matching procedure. The underlying assumption would be that the pre-computed covariate importances are good proxies for the accuracy of the regressions computed on covariate subsets. This may not hold, for example, in cases where variables are highly correlated.
Lastly, by default the estimate_CATEs argument of FLAME and DAME is set to FALSE and CATEs are not estimated during the matching procedure. Afterwards, when applying print or summary methods to the ame object returned by FLAME or DAME, CATEs are estimated and used to estimate average treatment effects. Typically, this takes negligible time; however, for very large datasets, estimating CATEs while matching by setting estimate_CATEs = TRUE will greatly accelerate printing and summarization of the resulting ame object.
Storage
The current implementation of FLAME and DAME is not capable of handling datasets with millions of rows and dozens of covariates due to memory constraints. A future release of the package will include a database implementation of the algorithms, allowing for matching in datasets too large to fit in memory and for faster matching on very large datasets in general. More details, see (Wang et al. 2020, Section 4.1).
Additional Features
Here we discuss additional considerations that may be taken into account when matching and highlight related package functionality along the way.
Matching With Replacement
In the code we displayed above, matching was by default performed without replacement, meaning that once a MMG is constructed for a unit, it cannot be matched again. We can toggle this behavior using the replace argument to FLAME and DAME:
FLAME_wo_replace <- FLAME_out # From previous run with replace = FALSE, as per the default
FLAME_w_replace <- FLAME(data, holdout, replace = TRUE)
#> FLAME stopping: predictive error would have risen 25% above the baseline.
Let’s start by comparing the main matched groups of an example unit, unit 32:
print(FLAME_wo_replace$MGs[[32]])
#> [1] 32 242
print(FLAME_w_replace$MGs[[32]])
#> [1] 32 242
In this case, they are the same. Using the MG function, however, allows us to look at all the matched groups a unit is part of by specifying multiple = TRUE:
print(MG(32, FLAME_wo_replace)) # run with multiple = FALSE bc no replacement
#> [[1]]
#> X1 X2 X3 X4 X5 treated outcome
#> 32 3 3 1 1 3 1 25.22405
#> 242 3 3 1 1 3 0 19.88697
print(MG(32, FLAME_w_replace, multiple = TRUE))
#> [[1]]
#> [[1]][[1]]
#> X1 X2 X3 treated outcome
#> 5 3 3 1 0 19.49019
#> 12 3 3 1 0 20.91604
#> 32 3 3 1 1 25.22405
#> 90 3 3 1 0 21.28322
#> 94 3 3 1 0 21.45683
#> 111 3 3 1 1 24.36747
#> 118 3 3 1 0 20.92010
#> 131 3 3 1 0 21.15464
#> 242 3 3 1 0 19.88697
#> 271 3 3 1 1 24.81733
#> 357 3 3 1 0 20.75999
#> 366 3 3 1 0 20.60477
#> 370 3 3 1 0 18.50099
#> 388 3 3 1 0 21.40572
#> 403 3 3 1 0 20.59634
#>
#> [[1]][[2]]
#> X1 X2 X3 X5 treated outcome
#> 12 3 3 1 3 0 20.91604
#> 32 3 3 1 3 1 25.22405
#> 90 3 3 1 3 0 21.28322
#> 94 3 3 1 3 0 21.45683
#> 242 3 3 1 3 0 19.88697
#> 271 3 3 1 3 1 24.81733
#> 366 3 3 1 3 0 20.60477
#> 370 3 3 1 3 0 18.50099
#>
#> [[1]][[3]]
#> X1 X2 X3 X4 X5 treated outcome
#> 32 3 3 1 1 3 1 25.22405
#> 242 3 3 1 1 3 0 19.88697
Again, we see that the main matched groups (the entries corresponding to matches on the greatest number of covariates) of each unit are the same. However, running on the data matched with replacement yields two more matched groups. We can see that whereas the units in the main matched group agree on X1 through X5, the secondary matched groups of unit 32 are of lower quality in that units only match on 3 or 4 covariates; they will thus be vulnerable by any confounding bias due to differing values of the remaining covariates.
Why then might we want to match with replacement? To see, let’s start by getting the additional units (and not their associated data) in one of the secondary matched groups of unit 32 from the matching with replacement. We can do this by specifying id_only = TRUE in the call to MG:
(unit32_MGs <- MG(32, FLAME_w_replace, multiple = TRUE, id_only = TRUE)[[1]])
#> [[1]]
#> [1] "5" "12" "32" "90" "94" "111" "118" "131" "242" "271" "357" "366" "370" "388" "403"
#>
#> [[2]]
#> [1] "12" "32" "90" "94" "242" "271" "366" "370"
#>
#> [[3]]
#> [1] "32" "242"
(only_in_secondary <- setdiff(unit32_MGs[[2]], unit32_MGs[[3]]))
#> [1] "12" "90" "94" "271" "366" "370"
Now let’s look at the matched groups formed for these units when we matched without replacement:
MG(only_in_secondary, FLAME_wo_replace)
#> [[1]]
#> NULL
#>
#> [[2]]
#> NULL
#>
#> [[3]]
#> X1 X2 X3 X4 X5 treated outcome
#> 94 3 3 1 2 3 0 21.45683
#> 271 3 3 1 2 3 1 24.81733
#> 370 3 3 1 2 3 0 18.50099
#>
#> [[4]]
#> X1 X2 X3 X4 X5 treated outcome
#> 94 3 3 1 2 3 0 21.45683
#> 271 3 3 1 2 3 1 24.81733
#> 370 3 3 1 2 3 0 18.50099
#>
#> [[5]]
#> NULL
#>
#> [[6]]
#> X1 X2 X3 X4 X5 treated outcome
#> 94 3 3 1 2 3 0 21.45683
#> 271 3 3 1 2 3 1 24.81733
#> 370 3 3 1 2 3 0 18.50099
We can see that when matching without replacement, only half of these units were matched! In this way they contribute nothing to our understanding of treatment effects in the data. Thus, while matching without replacement will only create matched groups of the highest possible quality for each unit, matching with replacement has the advantage of matching more units. There are also some differences as to the dependence induced between units that can affect how variance for treatment effect estimates is computed.
Note also that the MG column in the data entry of the resulting ame object does not exist:
FLAME_w_replace$data$MG
#> NULL
This is because when matching with replacement such a column is insufficient to describe the matched groups, unlike in the replace = FALSE case.
The PE - BF Tradeoff
As mentioned in the Introduction, FLAME drops covariate that lead to the greatest match quality, defined: $\mathtt{MQ} := C \cdot \mathtt{BF} - \mathtt{PE}$. The hyperparameter $C$ controls the weight given to making many matches and making high quality matches in the FLAME objective. In an extreme case, a value of $C$ = 0 only makes matches that are as high quality as possible; however, doing so may result in only very few units being matched. On the other extreme, $C$ tending to positive infinity will push FLAME to make as many matches as possible. To illustrate:
# early_stop arguments for illustration only
(FLAME_C_small <-
FLAME(data, holdout, C = 0.01,
early_stop_iterations = 4, early_stop_epsilon = Inf, verbose = 0))
#> An object of class `ame`:
#> FLAME ran for 4 iterations, matching 469 out of 500 units without
#> replacement.
#> The average treatment effect of treatment `treated` on outcome `outcome` is
#> estimated to be 4.6762678.
(FLAME_C_big <-
FLAME(data, holdout, C = 10000,
early_stop_iterations = 4, early_stop_epsilon = Inf, verbose = 0))
#> An object of class `ame`:
#> FLAME ran for 4 iterations, matching 489 out of 500 units without
#> replacement.
#> The average treatment effect of treatment `treated` on outcome `outcome` is
#> estimated to be 5.9484195.
We see that higher $C$ leads to more matches being made as that is the priority in the objective. However, the estimated ATE is around 5.9, compared to 4.7 from the small $C$ setting. For this simulated data, the true ATE is 5; more matches came at the expense of lower quality and therefore greater bias in estimating treatment effects.
We have found $C$ = 0.1 to be a good default. However, because the matching procedure in and of itself does not involve the outcomes of the matching data data, the output of FLAME can be compared across multiple choices of C to get a better sense of the data’s dependence on it.
Computing Predictive Error
By default, FLAME and DAME use ridge regression with 5-fold cross validation to compute PE from the holdout data. The other implemented option, selected by specifying PE_method = "xgb" uses gradient boosting, cross-validated over a wide range of parameter values to do so. However, a user may want to supply other functions, either for efficiency reasons or because they believe they are better suited to outcome regression for their data. This can be done by passing a function to the PE_method argument. This function must accept two arguments – a data frame of covariates and a vector of outcome values, in that order – and return a vector of in-sample predictions which, if the outcome is binary or multi-class, must be maximum probability class labels.
For example, we can compute PE using linear models as follows:
my_PE_linear <- function(X, Y) {
fit <- lm(Y ~ ., data = as.data.frame(cbind(X, Y = Y)))
return(fit$fitted.values)
}
FLAME_out <- FLAME(data = data, holdout = holdout, PE_method = my_PE_linear)
#> FLAME stopping: predictive error would have risen 25% above the baseline.
We emphasize that these functions must take in a data frame of covariates as their first argument. Many R implementations of machine learning algorithms require that covariates be passed in matrix form, with factor variables binarized. In such cases, the function passed to PE_method should convert the data frame appropriately, as with model.matrix. Such an example, in which LASSO is used to compute PE, is shown below:
my_PE_lasso <- function(X, Y) {
df <- as.data.frame(cbind(X, Y = Y))
X <- model.matrix(Y ~ ., data = df)
fit <- glmnet::cv.glmnet(X, Y, alpha = 1, nfolds = 5)
return(predict(fit, X))
}
FLAME_out <- FLAME(data = data, holdout = holdout, PE_method = my_PE_lasso)
#> FLAME stopping: predictive error would have risen 25% above the baseline.
If the outcome is binary or multiclass, the supplied function must return the maximum probability class instead of, for example, class probabilities. As an example, we use LASSO-penalized logistic regression with the outcome coded as binary 0-1 and ensure the predict method is called with argument type = 'class'.
# Recode the outcome to numeric 0 1
data$outcome <- ifelse(data$outcome > median(data$outcome), 1, 0)
holdout$outcome <- ifelse(holdout$outcome > median(holdout$outcome), 1, 0)
my_PE_lr <- function(X, Y) {
df <- as.data.frame(cbind(X, Y = Y))
X <- model.matrix(Y ~ ., data = df)
fit <- glmnet::cv.glmnet(X, Y, alpha = 1, nfolds = 5, family = 'binomial')
return(predict(fit, X, type = 'class'))
}
FLAME_out <- FLAME(data = data, holdout = holdout, PE_method = my_PE_lr)
#> FLAME stopping: predictive error would have risen 25% above the baseline.
The same should be done if the outcome is coded as a factor or if the outcome has more than 2 classes.
Early Stopping
By default, FLAME and DAME terminate when all covariates have been dropped or all control / treatment units have been matched. But there are various early stopping arguments that can be supplied to alter this behavior. In all cases, however, the algorithms still terminate if all covariates have been dropped or all control / treatment units have been matched, even if the user-specified stopping condition has not yet been met.
We can set a maximum number of iterations to run for via the early_stop_iterations argument. A value of 1, for example, corresponds to a single round of exact matching on all covariates:
(FLAME_exact <- FLAME(data, holdout, early_stop_iterations = 1))
#> FLAME stopping: completed 1 iterations
#> An object of class `ame`:
#> FLAME ran for 1 iterations, matching 192 out of 500 units without
#> replacement.
FLAME_exact$cov_sets # No covariate sets are dropped
#> [[1]]
#> NULL
The early_stop_epsilon argument is important for ensuring that matches are not made on sets of covariates too poor to predict the outcome well. If the matching algorithm attempts to drop a covariate that would raise the PE above (1 + early_stop_epsilon) times the baseline PE (the PE before any covariates have been dropped), it will terminate beforehand. It defaults to 0.25, which we have found to be a reasonable default, though we recommend performing the matching with multiple values of this argument. The predictive error at each iteration can be returned by specifying return_pe = TRUE as well. If a large spike is seen, relative to the scale of the outcome, a lower value of early_stop_epsilon can be set and those matches evaluated.
Handling Missing Data
Missingness is common in large, modern datasets; FLAME and DAME offer several options for how to handle missing values. Let’s start by adding some missingness to our data:
covs <- as.matrix(data[, 1:p])
inds <- sample(1:(n * p), size = round(0.05 * n * p), replace = FALSE)
covs[inds] <- NA
data[, 1:p] <- covs
The missing_data argument governs which of 3 methods should be used to handle missingness in the data to be matched. If missing_data = 'drop', units with any missing data are effectively dropped from the data and not matched:
FLAME_drop <- FLAME(data, holdout, missing_data = 'drop')
#> FLAME stopping: predictive error would have risen 25% above the baseline.
units_with_missingness <- which(apply(covs, 1, function(x) any(is.na(x))))
all(!FLAME_drop$data$matched[units_with_missingness])
#> [1] TRUE
We can see that any units with missingness are unmatched.
If missing_data = 'keep', the missing values are kept in the data; in this case, a unit can only match on sets containing covariates it is not missing. In a previous run that generated FLAME_out, before we introduced missingness, unit 57 matched on all covariates:
(57 %in% units_with_missingness) # an example unit
#> [1] FALSE
MG(57, FLAME_out)
#> [[1]]
#> X1 X2 X3 X4 X5 treated outcome
#> 20 1 2 2 2 3 0 0
#> 57 1 2 2 2 3 1 0
Running with missing_data = 'keep', we are still able to make matches on this unit, however only on a smaller subset of covariates which necessarily excludes any that unit 57 was missing:
DAME_keep <- DAME(data, holdout, missing_data = 'keep', verbose = 0)
print(data[DAME_keep$MGs[[57]], ])
#> X1 X2 X3 X4 X5 outcome treated
#> 20 1 2 2 2 3 0 0
#> 57 1 2 2 2 3 0 1
print(MG(57, DAME_keep))
#> [[1]]
#> X1 X2 X3 X4 X5 treated outcome
#> 20 1 2 2 2 3 0 0
#> 57 1 2 2 2 3 1 0
Lastly, running with missing_data = 'impute', missing values are imputed via MICE (mice::mice).
DAME_impute <- DAME(data, holdout, missing_data = 'impute', verbose = 0)
#> Starting imputation of `data` Finished imputation of `data`
print(DAME_impute$data[57, ])
#> X1 X2 X3 X4 X5 outcome treated matched weight MG
#> 57 1 2 2 2 3 0 1 TRUE 1 7
print(MG(57, DAME_impute))
#> [[1]]
#> X1 X2 X3 X4 X5 treated outcome
#> 20 1 2 2 2 3 0 0
#> 57 1 2 2 2 3 1 0
The unit has had a value imputed for X5 and now can make matches on that covariate. In practice, it might be good to impute missing data multiple times and look at the range of matches made across imputations.
For missingness in the holdout data, ‘drop’ and ‘impute’ flags can also be supplied to missing_holdout, where they ignore rows with missingness when computing PE and use imputed values to do so, respectively. The missing_holdout_imputations argument also controls how many imputations should be performed if missing_holdout = 'impute'; the predictive error at an iteration will be computed as the average across all iterations.
Conclusion
In this package, we present implementations of the DAME and FLAME algorithms for causal inference on discrete observational data. The algorithms are efficient and create high-quality, interpretable matches that can be used to estimate treatment effects, with many options for controlling how matches are to be formed, and tools for post-matching analysis. Future work will consist of a database implementation of these algorithms, allowing for analysis of datasets too large to fit in memory, treatment effect estimation for binary outcomes, the ability to parallelize PE computation, and more. Additional information on Almost Matching Exactly, including algorithms for mixed data, academic papers, and introductory videos, can be found on the Almost Matching Exactly website.
References
Dieng, Awa, Yameng Liu, Sudeepa Roy, Cynthia Rudin, and Alexander Volfovsky. 2019. “Interpretable Almost-Exact Matching for Causal Inference.” In The 22nd International Conference on Artificial Intelligence and Statistics, AISTATS 2019, 16-18 April 2019, Naha, Okinawa, Japan, 2445–53.
Morucci, Marco, Vittorio Orlandi, Sudeepa Roy, Cynthia Rudin, and Alexander Volfovsky. 2020. “Adaptive Hyper-Box Matching for Interpretable Individualized Treatment Effect Estimation.” Conference on Uncertainty in Artificial Intelligence (UAI), Https://Arxiv.org/Abs/2003.01805.
Parikh, Harsh, Cynthia Rudin, and Alexander Volfovsky. 2018. “MALTS: Matching After Learning to Stretch.” arXiv Preprint arXiv:1811.07415.
Wang, Tianyu, Marco Morucci, M. Usaid Awan, Yameng Liu, Sudeepa Roy, Cynthia Rudin, and Alexander Volfovsky. 2020. “FLAME: A Fast Large-Scale Almost Matching Exactly Approach to Causal Inference.” Journal of Machine Learning Research 21: 1–41. https://arxiv.org/abs/1707.06315.